5 Key Benchmarks That Prove Llama 3.3 70B Runs Efficiently on Arm Neoverse CPUs

Llama is an open and accessible collection of large language models (LLMs) tailored for developers, researchers, and businesses to innovate, experiment, and responsibly scale their generative AI ideas. The Llama 3.1 405B model stands out as the top-performing model in the Llama collection. However, deploying and utilizing such a large-scale model presents significant challenges, especially for individuals or organizations lacking extensive computational resources.
To address those challenges, Meta is introducing the Llama 3.3 70B model, which retains the same architecture as the Llama 3.1 70B model but incorporates the latest advancements in post-training techniques for greater model evaluation performance, while delivering notable improvements in reasoning, mathematics, general knowledge, instruction following, and tool use. Compared to the Llama 3.1 405B model, it offers similar performance, while being significantly smaller in size.
In close partnership with Meta, Arm’s engineering teams evaluated the inferencing performance of the Llama 3.3 70B model on Google Axion, a family of custom Arm64-based processors built on Arm’s Neoverse V2 technology, which are available through the Google Cloud. Google Axion is designed for higher performance, lower power consumption and greater scalability than legacy, off-the-shelf processors, which better prepares its data centers for the age of AI.
Our benchmarking shows that C4A virtual machines (VMs) based on Axion processors deliver seamless AI-based experiences when running Llama 3.3 70B model and achieve human readability levels across multiple user batch sizes. Human readability refers to the average speed at which a human can read text. This provides developers with flexibility to attain high-quality performance in text-based applications that is comparable to results produced with Llama 3.1 405B model, while no longer requiring large computational resources.
Optimizing Llama 3.3 70B Inference on Arm Neoverse CPUs for AI Scalability
Google Cloud offers Axion-based C4A VMs with up to 72 vCPUs and 576 GB of RAM. For these tests, we have used mid-range cost-effective c4a-standard-32 machine type to deploy the Llama 3.3 70B model with 4-bit quantization. For running our performance testing, we utilized the popular Llama.cpp framework, which as of version b4265 has been optimized with Arm Kleidi. The Kleidi integration provides optimized kernels to ensure AI frameworks can by default unlock the AI capabilities and performance of Arm CPUs.
Key Benchmark Results for Llama 3.3 70B on Google Axion:
- Prompt encoding speed remains stable at ~50 tokens/sec across batch sizes
- Token generation speed scales efficiently, leveraging SIMD optimizations (Neon, SVE, SDOT, MMLA)
- Supports human readability speeds for batch sizes up to 4 users
- Arm Kleidi integration in Llama.cpp improves inference performance
- Google Axion CPUs optimize AI workloads, reducing computational costs
Now let’s get a closer look at the results.
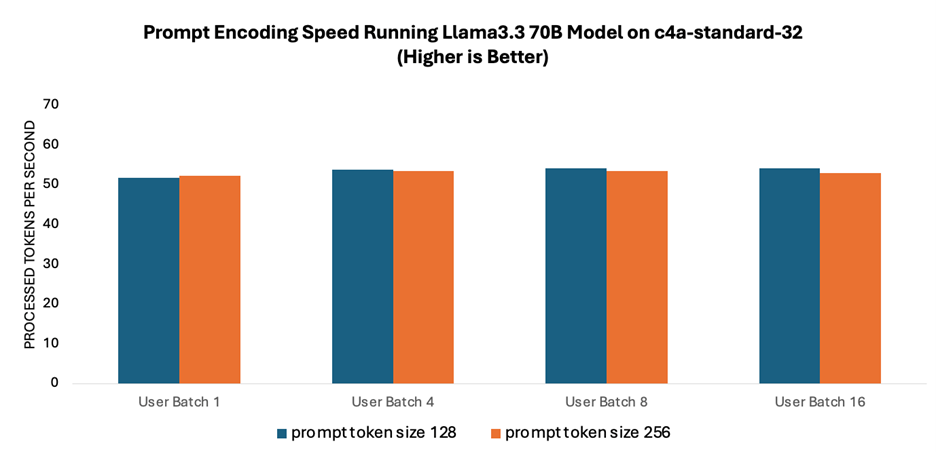
Prompt encoding speed refers to how quickly user inputs are processed and interpreted by the language model. As prompt encoding is done in parallel and leverages multiple cores, as shown in Figure 1, performance remains consistent at around ~50 tokens per second across various batch sizes, and the speed is comparable for the different prompt sizes tested.
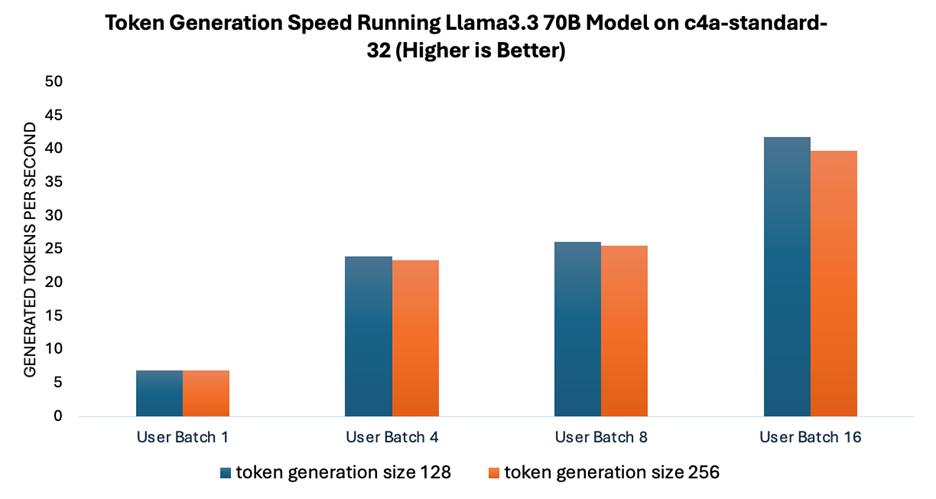
Token generation speed measures the rate at which the model generates responses when running Llama 3.3 70B model. Arm Neoverse CPUs optimize machine learning workflows with advanced SIMD instructions, such as Neon and SVE, that are designed to accelerate General Matrix Multiplication (GEMM). To further boost throughput, especially for larger batch sizes, Arm has introduced specialized optimization instructions like SDOT (Signed Dot Product) and MMLA (Matrix Multiply Accumulate).
As shown in Figure 2, the token generation speed increases with larger user batch sizes, while remaining relatively consistent across different token generation sizes tested. This capability to achieve higher throughput with larger batch sizes is essential for building scalable systems capable of serving multiple users effectively.
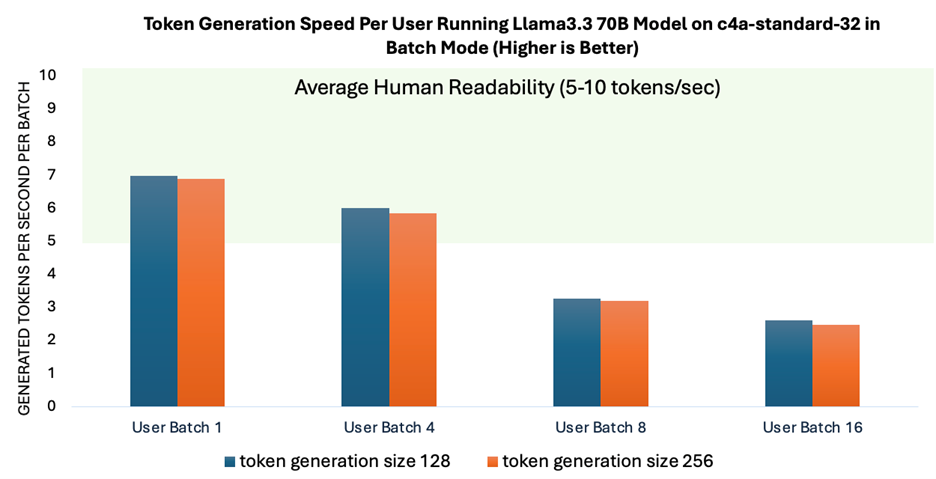
To evaluate the performance perceived by each user when multiple users are interacting with the model at the same time, we measured the token generation speed per batch. Token generation speed per batch is critical, as it directly influences the real-time experience during user interactions with the model.
As shown in Figure 3, the token generation speed reached an average human readability level for batch sizes up to 4, indicating that the performance remains stable as the system scales to accommodate multiple users. To accommodate larger numbers of concurrent users, leveraging serving frameworks like vLLM is beneficial, as these frameworks optimize KV cache management to enhance scalability.
A game-changer for generative AI
The new Llama 3.3 70B model is a potential game-changer in the accessibility and efficiency for utilizing the benefits of large-scale AI. The smaller model size makes generative AI processing more accessible to the ecosystem, with large computational resources no longer required. Meanwhile, the Llama 3.3 70B model helps to deliver more efficient AI processing that is vital for datacenter and cloud workloads, while delivering comparable performance to Llama 3.1 405B model in terms of model evaluation benchmark.
Through our benchmarking work, we have demonstrated how Google Axion processors, powered by Arm Neoverse, provide a smooth and efficient experience when running the Llama 3.3 70B model, delivering text generation with human-level readability across multiple user batch sizes tested.
We’re proud to continue our close partnership with Meta to enable open-source AI innovation on the Arm compute platform, helping to ensure that Llama LLMs operate seamlessly and efficiently across hardware platforms.
This blog also had contributions from Milos Puzovic, Technical Director, Arm, and Nobel Chowdary Mandepudi, Graduate Software Engineer, Arm.
The Arm Meta partnership
Learn more about how Arm and Meta are unlocking AI technologies together.

Any re-use permitted for informational and non-commercial or personal use only.
Editorial Contact



Latest on X
The future of AI infrastructure will be built as a system.
As AI workloads become more complex, performance alone isn't enough. Infrastructure must also be efficient, scalable and designed to work seamlessly across the stack.
At #COMPUTEX2026 @Rebellions_inc Co-founder & CTO

Today Arm hosted the Women in @TechworksHub: Engineering Intelligently event, bringing together innovators from across the technology industry to discuss leadership, transformation, and the future of talent in the AI era.
Alongside insights from Arm's Chief People Officer,



Congratulations to @Uber, @Nuro and @LucidMotors on announcing plans to bring robotaxi service to Houston in 2027.
Arm technology helps power the stack, from Nuro Driver on @nvidia DRIVE AGX Thor with Arm Neoverse V3AE CPUs, to Lucid Gravity's autonomous compute platform, to
At #COMPUTEX2026, @Lenovo showcased the Arm AGI CPU-based HR650a V3 Server.
Hear from John Donovan on why Arm was a natural fit and how the collaboration is helping deliver something different for AI and cloud infrastructure. https://okt.to/z8NG2S

Most AI conversations focus on the technology but there is so much more to consider.
Recently on the Human Capital Gains podcast, Arm CFO Jason Child shared a different perspective, exploring how leaders should think about AI adoption, productivity and measuring business impact.
The bottleneck in AI used to be humans.
In the agentic era, it’s compute.
That’s why we built the Arm AGI CPU. Mohamed Awad explains from the #COMPUTEX2026 show floor.

The bottleneck in AI used to be humans.
In the agentic era, it’s compute.
That’s why we built the Arm AGI CPU. Mohamed Awad explains from the #COMPUTEX2026 show floor.








