7 innovations from Arm that you shouldn’t miss from November 2025

Innovations in artificial intelligence (AI) and advanced compute continued to accelerate in November 2025, and Arm remained at the centre of that momentum. From new ways to run large language models (LLMs) on everyday devices to deeper architectural insights that shape next-generation performance, the month highlighted how Arm and our ecosystem are driving progress across mobile, graphics, automotive, and cloud.
Rethinking the CPU across AI workflows
Retrieval-Augmented Generation (RAG) combines two key parts of an AI workflow – retrieving relevant information from a knowledge base and generating responses using a LLM. In modern systems, this workflow relies on both the CPU – which handles data retrieval, filtering, and orchestration – as well as the GPU which manages the model inference.
Odin Shen, Principal Solutions Architect, explored this hybrid workflow on the NVIDIA DGX Spark platform, which pairs the Arm-based Grace GPU with the Blackwell CPU. Odin breaks down how Grace manages the retrieval and pipeline control, while Blackwell handles model execution, all supported by a unified memory architecture that reduces unnecessary data movement.
On-device audio generation with ExecuTorch and Stability AI
At October’s PyTorch Conference 2025, Gian Marco Iodice, Principal Software Engineer, demonstrated how users can generate audio, entirely on-device, using Stability AI’s Stable Audio Open Small model, which is powered by ExecuTorch.
Running entirely on an Arm-powered Android device, this demo showcases how ExecuTorch enables efficient, offline generative AI workloads directly on-device, with no cloud connectivity required. The application converts text prompts into high-quality 44 kHz audio, highlighting the power and flexibility of Arm CPUs for edge AI and creativity at scale.
Exploring LLMs on Android and ChromeOS with AI Chat
LLMs are increasingly running directly on devices rather than relying on cloud connectivity, offering faster responses, stronger privacy, and more predictable performance since all processing stays local. The challenge is often finding a simple way to evaluate different models on real hardware without setting up complex environments or dependencies.

Arm introduced AI Chat, a lightweight app that lets users explore and evaluate multiple LLMs directly on Android and ChromeOS devices. As explained by Han Yin, Staff AI Technology Engineer, AI Chat makes on-device testing accessible to a broader audience and removes friction from evaluating LLM performance by offering a clear, consistent environment that works across diverse Arm-powered devices. The app can also detect the device’s hardware, recommends suitable models, and shows real-time performance metrics such as tokens-per-second and time-to-first-token.
Introducing Arm Virtual FAE
When teams evaluate IP for a new chip or product, they often need clear explanations, comparisons, and guidance. This normally involves speaking with Field Application Engineers (FAEs) who help interpret specifications, answer technical questions, and explain trade-offs.
Matt Rowley, Senior Product Manager, introduces the Virtual FAE, an AI-powered assistant built directly into Arm IP Explorer. This means chip architects, engineers, and product teams now get a faster and more intuitive way to explore Arm IP, and users can get immediate clarity on the IP that fits their goals, whether they are designing edge devices, automotive platforms, or high-performance compute systems.
The next step in Arm CPU AI acceleration
Modern AI workloads rely heavily on matrix operations – the core mathematical building blocks behind neural networks, image processing, and signal analysis. Traditionally, these operations are handled by GPUs or dedicate accelerators, but CPUs also play a critical role. To keep pace with growing on-device AI demand, CPUs need built-in capabilities that make matrix math faster, more efficient, and easier for software to use.
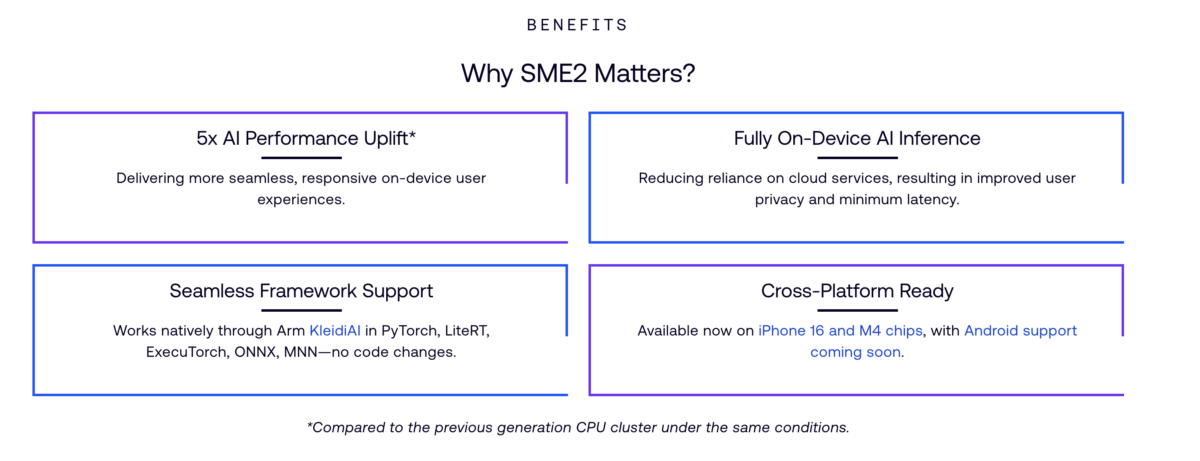
Arm Scalable Matrix Extension 2 (SME2) is Arm’s advanced matrix-processing extensions designed to accelerate AI and high-performance compute directly on the CPU. Zenon (Zhilong) Xiu, Senior Principal Applications Engineer, has now released a new technical breakdown that explains how SME2 works, why its design choices matter, and where it provides the biggest performance advantages. Xiu also covers LUT (lookup-table) enhancements, expanded vector handling, and the practical differences developers should expect in real workloads.
A clearer look at the future of automotive compute
Software-defined vehicles (SDVs) shift core vehicle functions into software that can be updated, improved, and expanded over time. As AI becomes central to perception, decision-making and in-cabin intelligence, the industry is now moving toward AI-defined Vehicles (AIDVs) in which real-time AI inference, sensor fusion and predictive behaviour shape how the vehicle responds to the world.
Prakash Mohapatra, Senior Product Manager, offers a deeper, more structured look at what AIDVs require from compute platform. The breakdown explains why AIDVs need scalable heterogeneous compute, how domain and zonal architectures change workload distribution, and which safety and real-time constraints designs must consider.
Understanding Vulkan Subpasses
Vulkan is a low-level graphics API designed to give developers more control over how rendering workloads are scheduled and executed. One of its features called subpasses, allows multiple rendering operations to be combined within a single render pass. Under optimal use, subpasses can reduce memory bandwidth, improve tiling efficiency, and boost performance on mobile GPUs. But when used in the wrong situations, they can introduce unnecessary complexity, stall pipelines or reduce clarity in the rendering flow.
Peter Harris, Distinguished Engineer, offers a practical, real-world explanation of subpasses — not just how they work, but when developers should or should not use them. This guidance goes further than standard API documentation by unpacking actual performance trade-offs, showing examples of optimal usage, and highlighting scenarios where subpasses deliver no benefit or even degrade performance.
Any re-use permitted for informational and non-commercial or personal use only.
Editorial Contact
Stay informed with Arm's top stories, insights, and conversations.



Latest on X
Open automotive software is shifting into its next gear. 🙌
SOAFEE has grown from 13 founding members to 150+ organizations since 2021.
As it joins @corecollectivee, Arm remains an active contributor and governing member, helping advance automotive and physical AI.

Congratulations to @NVIDIA on a major Vera Rubin milestone. 👏
Backed by 300 global partners and built around the Arm-based Vera CPU, the platform shows how compute designed for modern AI infrastructure can move beyond the limits of legacy, off-the-shelf CPUs.

🚀 The NVIDIA Vera Rubin platform is here, with 10x better performance per watt.
➡️ The NVIDIA ecosystem, including @CoreWeave, @GoogleCloud, @Microsoft, and @Oracle Cloud, are standing up NVIDIA Vera Rubin NVL72 to deliver the lowest token cost for the agentic era.
➡️ NVIDIA
For Jason Child, joining Arm was a “once-in-a-lifetime opportunity.”
Jason joins the Secrets of Rockstar CFOs podcast by @stratcfo360 to discuss his journey, going public and our extension into silicon.
Listen to the full conversation on Spotify: https://okt.to/e9NbfM
Congratulations to @XPENG_Global on the launch of the all-new #XPENGL03. 👏
The next-generation AI SUV coupe brings new intelligent driving and connected in-car experiences to XPENG’s global portfolio.
We’re excited to be part of the ecosystem enabling the next generation of

XPENG evolves into a global Physical AI company.
Meet the all-new XPENG L03.
Featuring the European debut of XPENG NGP.
In Europe, For Europe.
$XPEV
In an ecosystem as broad as ours, there's no single path to innovation.
We understand that different workloads, business goals, and stages of development call for different approaches - which is why we're continuing to expand the ways our partners can build on Arm. 💡

Congratulations are in order for Arm CEO Rene Haas on being named to the Observer's 2026 AI Power Index.
As AI demand continues to grow, so does the need for compute platforms and infrastructure that enable AI at scale.
This recognition highlights the leaders shaping the

Organizations need the flexibility to build, deploy, and scale AI in the way that works best for them. That means supporting different business goals, different deployment models, and different levels of integration.
A strong compute ecosystem should enable organizations to:







