Eight Questions (and Answers) About Specialized Processing

Specialized processing represents future of the semiconductors and, by extension, system design and software development. Although it’s a powerful concept, it is also often not fully understood. To answer your questions (even if you didn’t know you had any) we’ve compiled some answers:
What is specialized processing?
Also termed ‘Heterogenous Computing’, specialized processing involves creatively combining different types of processor cores to extend performance gains. The concept embodies integrating CPUs and GPUs into the same system-on-a-chip (SoC), creating a single processor that combines high-performance and efficiency-optimized CPUs to maximize performance-per-watt. It could even mean shifting from designing data centers around CPUs to designing them around a mix of CPUs, DPUs, FPGAs, GPUs and other processors.
To put it another way, in specialized processing design replaces transistor density as the main means for moving the needle forward.
What’s the benefit?
Better overall performance and better application-specific performance. While traditional server CPUs can conduct AI training, GPUs with their ability to run more tasks in parallel are better suited for the job.
Similarly, Data Processing Units (DPUs) can perform networking, storage, and security tasks more efficiently than a CPU. A single NVIDIA Bluefield-3 DPU, for instance, will be capable of performing the same amount of work when it comes to those tasks as up to 300 traditional CPU cores.
The savings can be measured in multiple ways. By switching to DPUs, a cloud provider frees up CPU cores, which can then be deployed for revenue-generating tasks. More work gets accomplished with less energy and rack space, thereby lowering cost at the same time. Cloud providers can then tell their customers that their carbon-per-operation is lower, along with their costs, helping them with their own sustainability and profit goals while cementing the commercial relationship.
Anything else?
Yes. You can’t have an edge without specialized processing. Edge devices differ from traditional data center servers or desktop PCs in their greater need for robustness. Content providers will install edge servers in urban corridors to cut the bandwidth and energy to stream movies or other data-intensive tasks while improving overall service. For the economic model to work, however, these servers need to emit little heat, occupy little space and largely operate without human oversight.
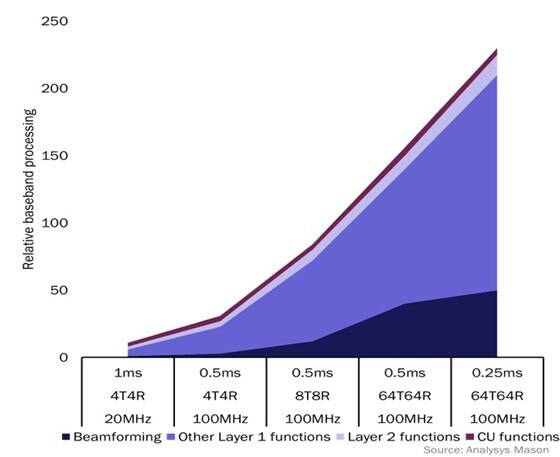
It will play a big role in 5G as well. Layer 1 functions such as beamforming performed by the radio unit will require a 150x boost in processing power over the next five years. (See diagram below). This increase, however, will have to occur within the same existing 5 watt envelope. Trying to wring that level of performance out of traditional designs while staying within the prescribed boundaries won’t work. With 5G we will see multicore server-class devices managing dozens of radios in the wild.
Is it a luxury or necessity?
A necessity. It’s a point most easily understood by looking at data centers. From 2000 to 2005, data center power consumption—along with the number of data centers—shot up by nearly 90%. Alarmed, data center owners began to do things like place plastic sheeting over data center racks to manually channel waste heat and reduce cooling loads. Virtualization and workload consolidation helped further increase power use effectiveness. Just as important, Moore’s Law continued on its magical path allowing performance to increase within a reasonable power envelope.
The results exceeded most expectations. Data center workloads and IP traffic grew by 8x and 12x, respectively, between 2010 and 2020 yet power only grew by 6% in total. Put another way, Netflix, Facebook, Salesforce, TikTok and AWS all became larger than life presences in our world during the decade, and the power meter barely moved.
When was specialized processing born?
You could argue that it’s always been around. Math co-processors were a thriving market in the early days of PCs before being sucked into the CPU.
Today’s version of specialized processing, however, can arguably be said to have started in 2006. Annual performance gains on integer and floating point benchmarks slowed to 17% to 25%, respectively. Researchers such as William Gropp at the University of Illinois also noted that Dennard scaling started to hit a wall in 2006 with frequency increases became more and more scarce.
Meanwhile, NVIDIA released the GeForce 8800, its first graphics card targeted at high-performance computing in August that year. At the time, inserting GPUs into servers was a novel concept. Within a few years, however, GPU-enhanced supercomputers such as Tianhe and Jaguar sat atop the Top500 list. powered by NVIDIA chips, topped the Top500 list. Now, approximately two-thirds of systems on the list rely on GPUs.
Specialized concepts began to percolate in other markets as well. Falanx, a pioneer in mobile GPUs, was acquired by Arm in 2006 as well. We released our first Mali GPU in February 2007.
Innovations continued to come. In 2011, we later introduced our big.LITTLE technology which encouraged SoC designers to combine high-performance cores for managing compute intensive tasks, such as gaming and web browsing, with energy-efficient cores for lower-intensity tasks, like messaging and email, and for an overall optimal performance balance. Big.LITTLE is now standard practice. In fact, it is now the most commonly used heterogeneous processing architecture for consumer devices worldwide.
Also in 2011, Annapurna Labs – the startup that became instrumental in developing the Graviton server CPU its Nitro system, arguably the first DPU system to achieve mass popularity – launched as well.
But won’t a switch to specialized be expensive?
General purpose processors do have more potential opportunities, allowing design and manufacturing costs to be spread over a wider base. Unfortunately, the performance improvement per dollar has been declining, as show in this chart extrapolated from data presented by John Hennessy and David Patterson in 2018:
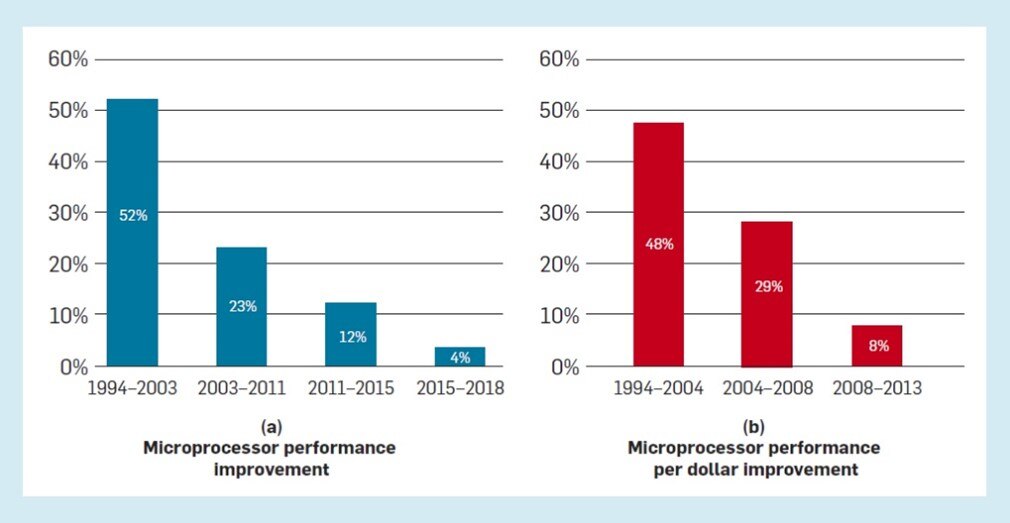
Lower performance gains in turn leads to lower adoption rates and turnover. PC replacement rates have expanded from every 4 to every 5 to 6 years in the last few years while smartphone upgrades have grown from 23 to 31 months.
Where else will it be used?
You’ll see it in all markets: automotive, IoT etc. And you’ll see it in new product categories. Computational storage involves integrating small, efficient processors directly into solid-state storage to perform tasks like image recognition closer to where the data resides. Not only can computational storage improve performance, it can dramatically cut power. By some estimates, 62% of all system power gets consumed moving data from storage to memory to a CPU and back. Computational storage cuts the commute.
What are some future manifestations?
Steve Furber, one of the individuals who developed the Arm 1 back in the late 80s, is working on SpiNNaker, a single chip that contains around 10 million Arm CPUs. SpiNNaker is designed for the most difficult AI tasks. It works through a concept called event-based processing that effectively allows the cores to operate in a semi-autonomous manner.
Similarly, we could see FPGA-like technology integrated into processors that would allow device makers to perform hardware upgrades remotely.
What is Total Compute?
Arm’s Total Compute strategy is a holistic system-based approach to chip design that lets semiconductor designers, OEMs and developers extract the maximum amount of performance.
Any re-use permitted for informational and non-commercial or personal use only.
Editorial Contact



Latest on X
#ArmEverywhere marked a defining shift in the Arm compute platform.
For more than 30 years, the industry has built on Arm, from IP to Compute Subsystems. Now, we've taken the next step.
The introduction of the Arm AGI CPU, marks our extension into production silicon for the
This week, the Arm AGI CPU lit up the @Nasdaq tower, marking a new chapter as we extend the Arm platform into production silicon for the first time. ✨
Built for the era of agentic AI, it’s designed to power the next generation of AI infrastructure at scale. #ArmEverywhere

A defining moment for AI compute in just 60 seconds.
At #ArmEverywhere, Arm moved expanded into production silicon with the Arm AGI CPU—joined on stage by @Meta and @OpenAI.
Built for the rise of agentic AI, this is a big step—bringing Arm into data center silicon for the first

Breakfast in one office ☕
Pizza in another 🍕
Cakes everywhere 🎂
Teams around the world tuned in together to mark the next chapter for Arm — extending our compute platform into production silicon, with the launch of the Arm AGI CPU. #ArmEverywhere

Behind the Arm AGI CPU is a team pushing boundaries.
Passion. Resilience. Determination.
A pivotal moment as Arm moves into production silicon and the next chapter of our compute platform.
This is what innovation looks like. #ArmEverywhere

In an exclusive first look at our new Austin lab, @CNBC highlights Arm’s entry into production silicon with the Arm AGI CPU.
In the video, they explore how the Arm AGI CPU is built for AI inference in data centers and the growing role of CPUs in scaling AI
Arm in the data center just works.
With 15+ years of software ecosystem investment and 1.25B+ Neoverse cores deployed, the foundation is clear.
At #ArmEverywhere, Mohamed Awad shared more on the industry leaders supporting our next chapter. More in the blog here:








