Redefining Technology with Smart Vision, Large Language Models, and AI

Noam Chomsky, a pioneer in linguistics and cognitive science, once said that human language is unique and unparalleled in the animal world. Now, the rapid development of large language models (LLMs) and generative AI, such as GPT-3.5, 4.0, and Bert, has made language possible for machines, greatly expanding their capabilities. This raises the question: where do we go from here?
The Evolution of Intelligence Creating New Computing Paradigms
To imagine how AI and large language models evolve, we need to look no further than ourselves. We human beings change the world through a dynamic interplay of our senses, thoughts, and actions. This process involves perceiving the world around us, processing information, and then responding through deliberate actions.
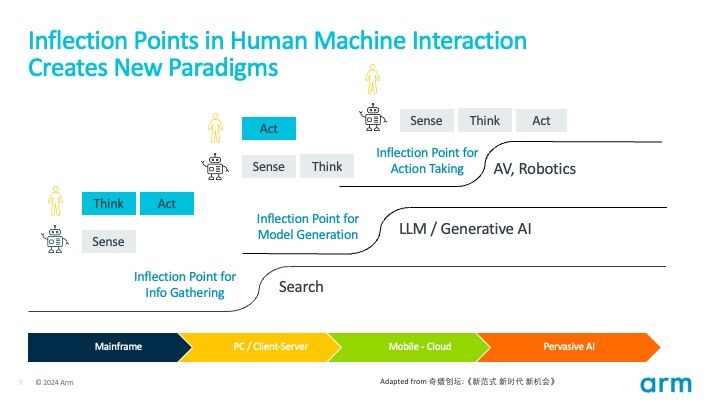
Over the history of computing, we have witnessed the gradual transfer of abilities such as perception, thinking, and action – once exclusive to humans – to machines. Each inflection point in the transfer of these abilities will give rise to new paradigms.
In the late 20th century, great companies like Google rendered information-acquisition cost from marginal to fixed, meaning it costs money for Google to crawl the web and index the information, but for every one of us to find the information, it is almost zero cost. Machines could take over humans as our information system. This ushered in the Internet era and the subsequent era of mobile internet, which changed the way people access, disseminate, and share information. It has had a profound impact on fields such as business, education, entertainment, and social interaction, among many others.
And now, we are witnessing a new inflection point where thinking, reasoning, and model construction shifts from humans to machines. OpenAI and large models transform the cost of producing models from marginal to fixed.
Large models have been trained on vast amounts of text, image, video from the Internet, which includes information from diverse fields such as law, medicine, science, arts, and many others. This extensive training allows these big models to serve as foundational models to more easily construct other models.
This inflection point will inevitably spark a proliferation of models, whether they are cognitive (how we see, and speak), behavioral (how to drive a car), or domain-specific models (how to design semiconductor chips). Models represent knowledge, and this inflection point will make models and knowledge ubiquitous, accelerating the arrival of the next inflection point – The era where machines such as autonomous vehicles , autonomous mobile robots and other robots such as humanoids perform actions in all kinds of industries and deployment scenarios. These new paradigms will redefine human-machine interaction.
Multimodal large language models and the critical role of Vision
With transformer models and their self-attention mechanism, AI can become truly multimodal, meaning the AI systems can process input from multiple modes such as speech, images, and text, just like us human beings.
OpenAI’s CLIP, DALL·E, Sora and GPT-4o are examples of models that take steps toward multimodality. CLIP, for instance, understands images paired with natural language, allowing it to bridge visual and textual information. DALL·E is designed to generate images from textual descriptions, and Sora can generate videos from text, promising to get to a world simulator. GPT-4o took it one step further: OpenAI trained GPT-4o as a single new model across text, vision, and audio end to end without converting multimedia to and from text. All inputs and outputs are processed by the same neural network to enable the model to reason across audio, vision, and text in real time.
The future of multimodal AI will be on the edge
AI innovators have pushed the boundaries of where models can operate, driven by edge hardware advancements (many developed on Arm), latency concerns, privacy and security requirements, bandwidth and cost considerations, and the need for offline capabilities during intermittent or absent network connections. Even Sam Altman himself admitted that for video (what we perceive through vision), an on-device model might become critical to deliver the desired user experience.
However, resource constraints, model size, and complexity challenges hinder the move of multimodal AI to the edge. Addressing these issues will likely require a combination of hardware advancements, model optimization techniques, and innovative software solutions to make multi-modal AI prevalent.
The profound impact of the recent AI developments on computer vision is especially intriguing. Many vision researchers and industry practitioners are using large models and transformers to enhance vision capabilities. Vision can also be increasingly critical in the large model and action eras.
Why?
- Machine systems must understand their surroundings through senses like vision, providing essential safety and obstacle avoidance capabilities for autonomous driving and robots, which is a matter of life and death. Spatial intelligence is a hot area for researchers such as Fei-fei Li, broadly regarded as the godmother of AI.
- Vision is also crucial for human-machine interaction. AI companions not only need a high IQ but also a high “EQ.” Machine vision can capture human expressions, gestures, and movements, to better understand human intentions and emotions.
- AI models require vision capabilities and other sensors to gather real-world data and adapt to specific environments, which is particularly important as AI moves from light to heavy industries where digitization levels have been lower.
Vision + Foundational Models: A Few Examples
Although ChatGPT gained popularity due to its language capabilities, leading large language models (LLMs) have evolved to become multimodal, making the term “foundational models” more appropriate. The field of foundational models, which encompasses various modalities, including vision, is developing rapidly. Here are a few:
DINOv2
DINOv2 is an advanced self-supervised learning model developed by Meta AI, which builds upon the foundation of the original DINO (DIstillation of NOisy labels) model. It has been trained on a vast dataset of 142 million images, which helps improve its robustness and generalizability across different visual domains. DINOv2 is capable of segmenting objects, without having ever been trained to do so; also it produces universal features suitable for image-level visual tasks (image classification, video understanding) as well as the pixel-level visual tasks (depth estimation, semantic segmentations), impressively versatile!
SAM (Segment Anything Model)
SAM is a promotable segmentation system with zero-shot generalization to unfamiliar objects and images, without the need for additional training. It can identify and segment objects within images using various input prompts to specify what to segment. This allows it to operate without requiring specific training for each new object or scene it encounters. According to Meta AI, SAM can produce segmentation results in as little as 50 milliseconds, making it practical for real-time applications. Its versatility allows it to be used across a variety of fields, from medical imaging to autonomous driving.
Stable Diffusion
Generating images and videos from textual descriptions is an important aspect of GenAI as it not only enables new forms of creativity, but also promises to build a world simulator. World simulators can serve as the foundation for training simulations, educational programs, or video games. Stable Diffusion is a type of generative AI model known for its ability to create images from textual descriptions. This model uses a technique called latent diffusion, which operates efficiently by manipulating images in a compressed format called latent space rather than directly in pixel space. This approach helps in reducing the computational load, allowing the model to generate high-quality images more quickly.
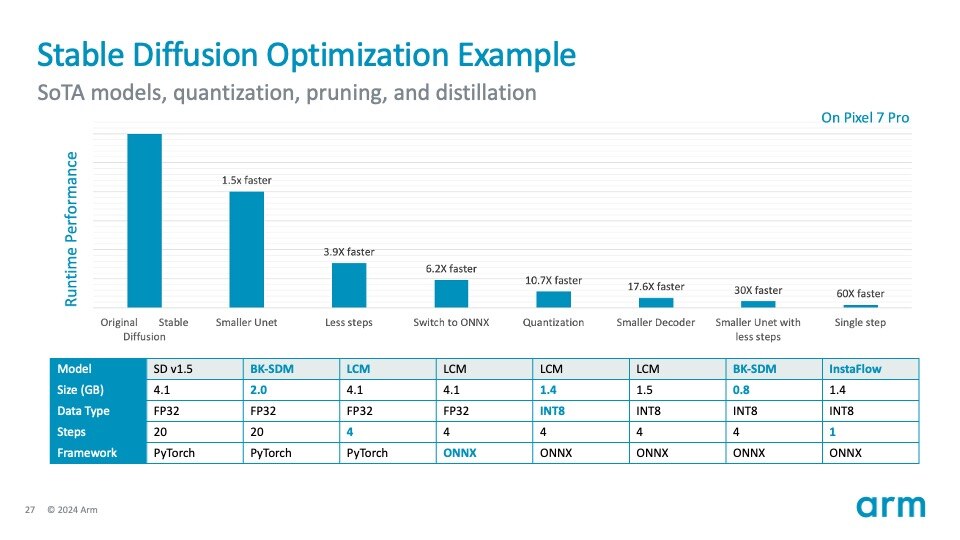
Stable Diffusion can already run on the edge on smart mobile devices. The above shows an example of Stable Diffusion optimization journey:
- Taking Stable Diffusion as it is, you wouldn’t run it on mobile CPU or NPU (using 512×512 image resolution based).
- By using a smaller U-Net architecture, fewer sampling steps, switching to ONNX format, applying quantization (FP32 to int8), and employing other techniques, it has shown more than a 60x speed-up on the CPU alone. Many of these optimization techniques and tools are developed by Arm’s wide ecosystem. There is still room to optimize it even further.
Axera’s pursuit of better Vision with multimodal large language models
One of Arm’s partners, Axera, has demonstrated deploying a DINOv2 vision transformer at the edge on its flagship AX650N chipset. The chip uses Arm Cortex-A55 CPU cluster for pre- and post-processing, in combination of Axera’s Tongyuan mixed-precision NPU and AI-ISP, to deliver high performance, high precision, ease of deployment and excellent power efficiency.
This video shows the effect of running DINOv2 on AX650N.
Vision transformers offer better generalization to new and unseen tasks when pretrained on large and diverse datasets, simplifying retraining and shortening finetuning time.
They can be more adaptable to various tasks beyond image classification, such as object detection and segmentation, without substantial architecture changes.
Embracing the Future of AI and HMI
Thanks to AI and evolving large language models, we’re on the cusp of a transformative shift in technology and human interaction. Vision plays a crucial role, enabling machines to navigate and interpret their surroundings, ensuring safety and enhancing interaction. The move towards edge AI promises efficient, real-time applications, driven by advancements in hardware and software.
(Catherine Wang, principal computing vision architect with Arm, contributed to this article)

Any re-use permitted for informational and non-commercial or personal use only.
Editorial Contact
Stay informed with Arm's top stories, insights, and conversations.



Latest on X
Congratulations to @NVIDIA on a major Vera Rubin milestone. 👏
Backed by 300 global partners and built around the Arm-based Vera CPU, the platform shows how compute designed for modern AI infrastructure can move beyond the limits of legacy, off-the-shelf CPUs.

🚀 The NVIDIA Vera Rubin platform is here, with 10x better performance per watt.
➡️ The NVIDIA ecosystem, including @CoreWeave, @GoogleCloud, @Microsoft, and @Oracle Cloud, are standing up NVIDIA Vera Rubin NVL72 to deliver the lowest token cost for the agentic era.
➡️ NVIDIA
For Jason Child, joining Arm was a “once-in-a-lifetime opportunity.”
Jason joins the Secrets of Rockstar CFOs podcast by @stratcfo360 to discuss his journey, going public and our extension into silicon.
Listen to the full conversation on Spotify: https://okt.to/e9NbfM
Congratulations to @XPENG_Global on the launch of the all-new #XPENGL03. 👏
The next-generation AI SUV coupe brings new intelligent driving and connected in-car experiences to XPENG’s global portfolio.
We’re excited to be part of the ecosystem enabling the next generation of

XPENG evolves into a global Physical AI company.
Meet the all-new XPENG L03.
Featuring the European debut of XPENG NGP.
In Europe, For Europe.
$XPEV
In an ecosystem as broad as ours, there's no single path to innovation.
We understand that different workloads, business goals, and stages of development call for different approaches - which is why we're continuing to expand the ways our partners can build on Arm. 💡

Congratulations are in order for Arm CEO Rene Haas on being named to the Observer's 2026 AI Power Index.
As AI demand continues to grow, so does the need for compute platforms and infrastructure that enable AI at scale.
This recognition highlights the leaders shaping the

Organizations need the flexibility to build, deploy, and scale AI in the way that works best for them. That means supporting different business goals, different deployment models, and different levels of integration.
A strong compute ecosystem should enable organizations to:
Autonomous robots are beginning to reshape how construction work gets done. 🧱🤖
As physical AI takes on more complex tasks, the compute beneath these systems becomes critical, delivering the performance, efficiency and software ecosystem needed to scale.







